Master's Thesis: Day-to-Night Image Translation with CycleGAN and Time-Lapse Training

This project focused on possible enhancements of CycleGAN, an
unsupervised learning technique, for day-to-night image translation. A
basic introduction to CycleGAN can be found
here.
This research also explored the possibility of incorporating
time-lapse data into the training process, with the end goal of
generating synthetic time-lapse sequences. The thesis was split into
three main parts:
- Optimising basic CycleGAN for day-to-night image translation
- Experimenting with architectural changes and content-style disentanglement
- Using a novel network architecture to generate synthetic time-lapses
Throughout the project, model performance was evaluated both
qualitatively (by inspecting for visual artefacts) and quantitatively
using perceptual metrics specifically designed to quantify the
performance of models in image generation. Specifically, the Fréchet
Inception Distance (FID) and Kernel Inception Distance (KID) were used.
1. Optimising basic CycleGAN for Day-to-Night Image Translation
An optimised CycleGAN model for day-to-night image translation was developed by adapting the architecture of the CycleGAN generator so that transfer learning could be exploited.
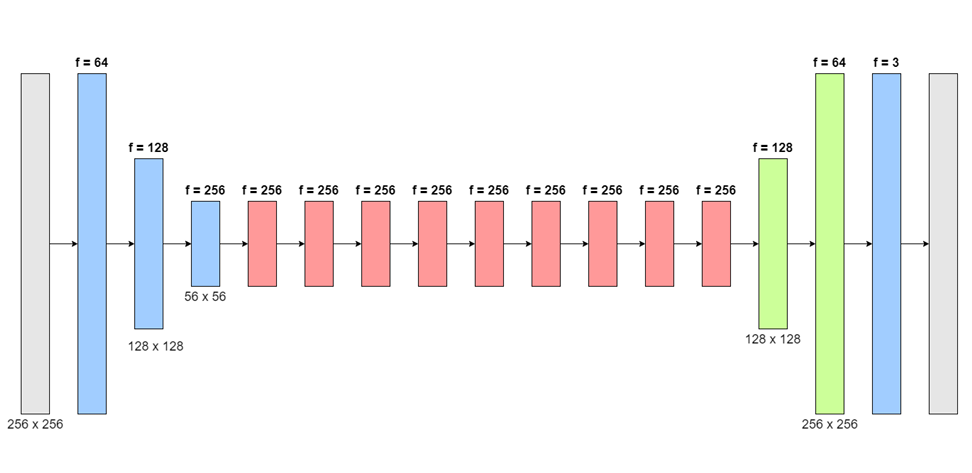
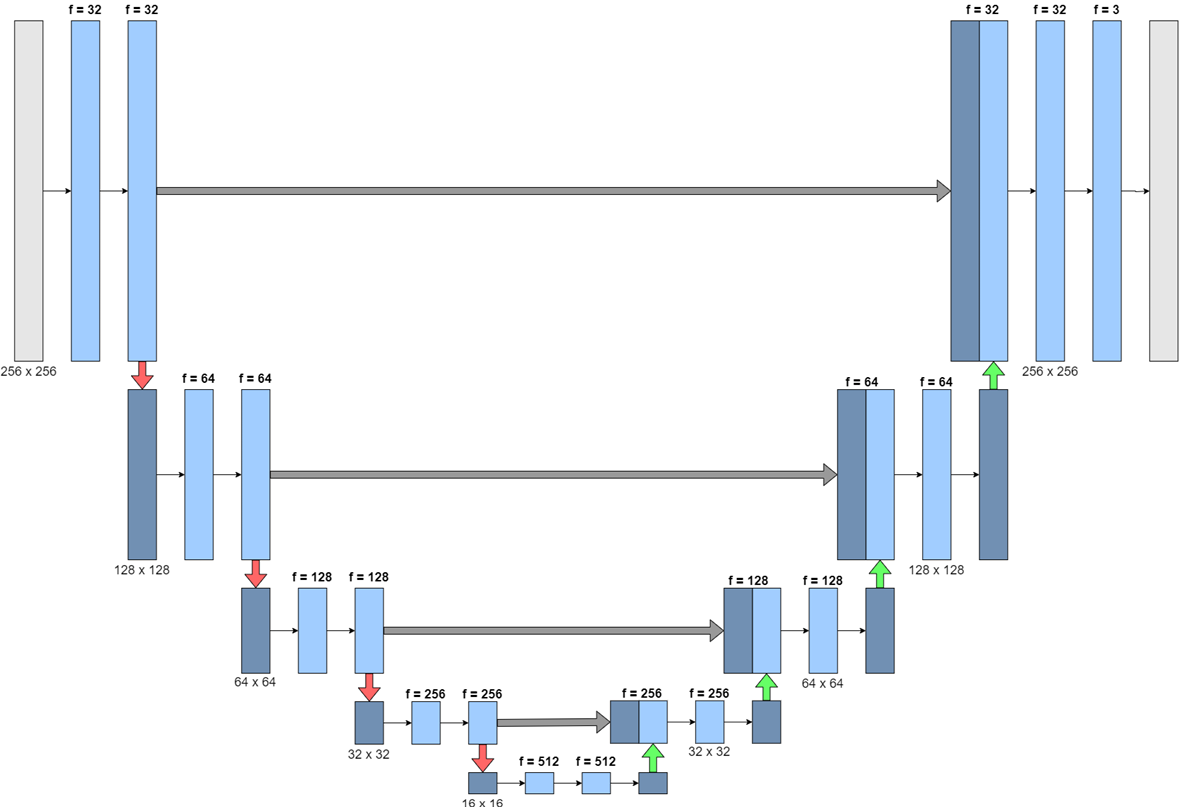
Based on the belief that a pre-trained encoder might improve the network's ability to extract high-level features, the generator architecture was altered to a U-Net structure. This U-Net generator architecture could then be compared against the original CycleGAN generator, before the inclusion of a pre-trained component in the network.
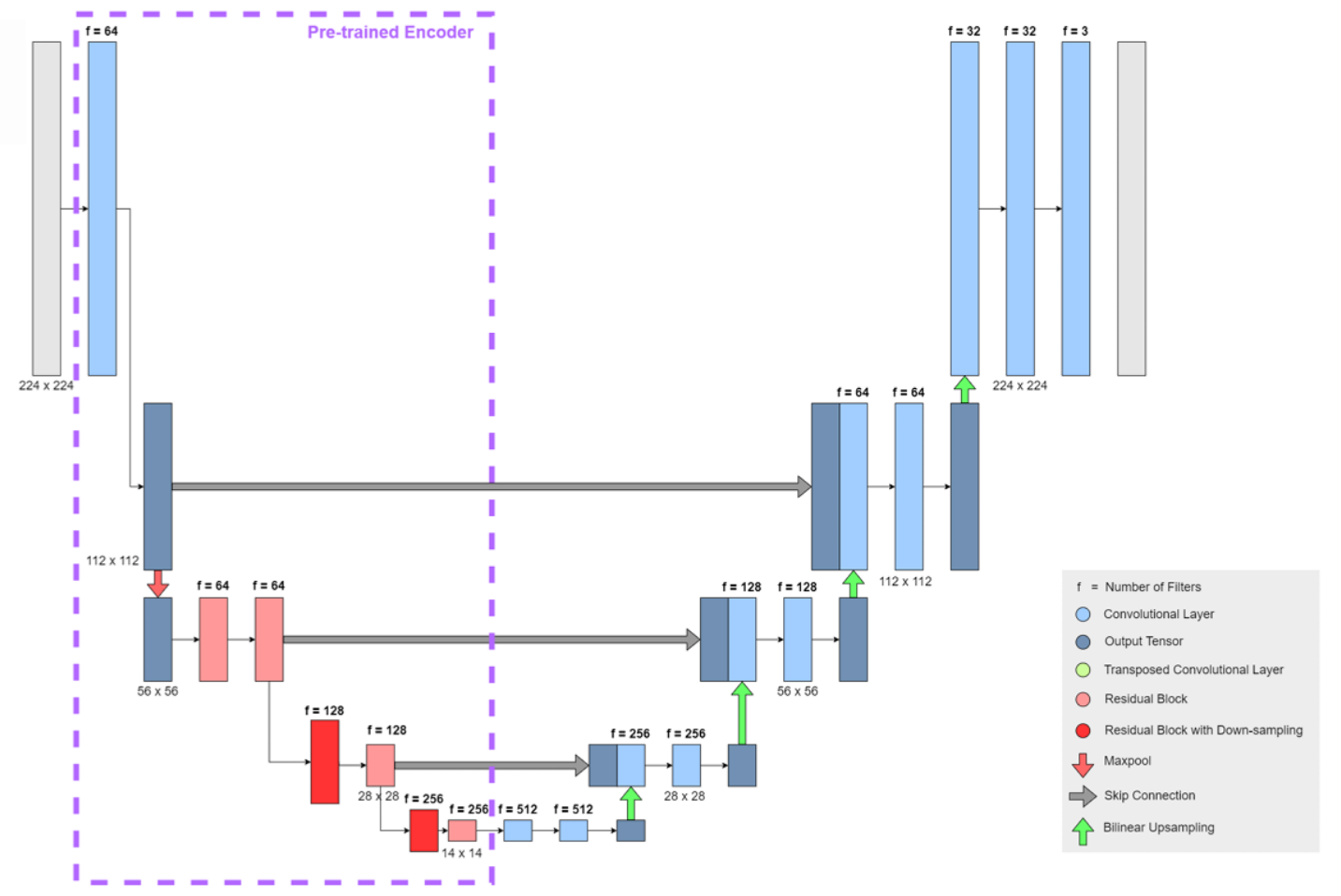
Having implemented a basic U-Net generator architecture, the final step was to substitute the encoder portion of the network with a pre-trained network capable of extracting high-level features. The ResNet-18 model was selected for this purpose, as its size is roughly proportionate to the rest of the network.
A comprehensive comparison of these three generator architectures was performed, with the network with a pre-trained encoder displaying the strongest performance. A comprehensive analysis of the three models can be found in the paper linked above.
2. Architectural Changes and Content-Style Disentanglement
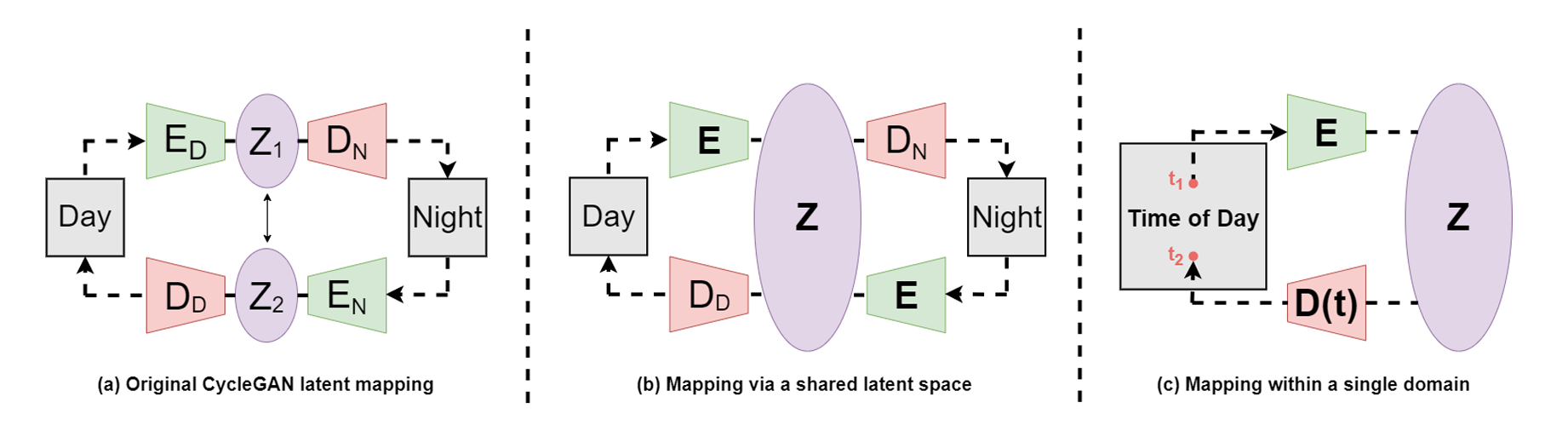
The use of a pre-trained encoder raises the interesting question as to the possibility of using a single encoder across both the forward and reverse mappings of the CycleGAN network. A single, shared encoder would constrain the two mappings, forcing the network to map both day and night input images into a single, shared latent space. This would encourage the network to disentangle the underlying content of input images (buildings, trees, etc.) from the style of the image (daytime or night-time lighting conditions).
The disentanglement of content from style not only increases the
explainability of the network; it may also serve to improve the
overall quality of the translation. Through increasing the constraints
on the network encouraging it to preserve the underlying content of
the input image, the final output quality may be improved. To
investigate this, a novel loss term was proposed: the
mid-cycle loss. For a full discussion of the effects of this
term, refer to my research paper.
Finally, the ability of a network with a single, shared encoder
to perform comparably to a network with dedicated encoders for each
mapping raises the question of the viability of using a single
generator for both mappings (sharing both the encoder and the
decoder). By conditioning the decoder on a timestamp input, a single
generator may learn to map input images into both the daytime and
night-time domains. Therefore, a network with a single generator was
also implemented and analysed.
3. Synthetic Time-Lapses
The novel network architecture with a single generator is capable not only of mapping to both daytime and night-time, but also to intermediate points between these two extremes due to the timestamp input. Theoretically, this should enable the network to learn how to generate time-lapse sequences. To investigate this possibility, the network was trained using time-lapse data.
Due to a very small amount of time-lapse training data, it was
not possible to train the network from scratch using only time-lapse
data. To work around this, the network was first trained using a large
day-night dataset, before performing a secondary training phase to
fine-tune the network using time-lapse data. A full discussion of the
results can be found in my research paper, which is available for
download above.
